La combinazione di controlli computazionali con testo naturale rivela nuovi aspetti della composizione del significato
Mariya Toneva , Tom M. Mitchell ,
Leila Wehbe
Fonte:https://doi.org/10.1101/2020.09.28.316935
Ora pubblicato su Nature Computational Science doi: 10.1038/s43588-022-00354-6
Astratto
Per studiare una componente fondamentale dell'intelligenza umana – la nostra capacità di combinare il significato delle parole – i neuroscienziati cercano correlati neurali della composizione del significato, come l'attività cerebrale proporzionale alla difficoltà di comprensione di una frase. Tuttavia, si sa poco sul prodotto della composizione del significato, ovvero il significato combinato delle parole al di là del loro significato individuale. Chiamiamo questo prodotto "significato sovra-parola" e ne ideiamo una rappresentazione computazionale utilizzando recenti algoritmi di reti neurali e una nuova tecnica per distinguere il significato composto da quello delle singole parole. Utilizzando la risonanza magnetica funzionale, riveliamo che gli hub che si ritiene elaborino il significato a livello lessicale mantengono anche il significato sovra-parola, suggerendo un substrato comune per la semantica lessicale e combinatoria. Sorprendentemente, non siamo in grado di rilevare il significato sovra-parola nella magnetoencefalografia, il che suggerisce che il significato composto sia mantenuto attraverso un meccanismo neurale diverso dall'attivazione sincronizzata. Questa differenza di sensibilità ha implicazioni per i risultati passati della neuroimmagine e per la futura neurotecnologia indossabile.
Introduzione
Comprendere il linguaggio nel mondo reale richiede di comporre il significato delle singole parole in modo che il prodotto finale composto abbia più significato della sequenza di parole isolate. Ad esempio, interpretiamo l'affermazione "Mary ha finito la mela" come se Mary avesse finito di mangiare la mela, anche se "mangiare" non è specificato esplicitamente ( Pylkkänen, 2020 ). Questo significato sovra-parola, o prodotto della composizione di significato al di là del significato delle singole parole, è al centro della comprensione del linguaggio, e le sue basi neurobiologiche e i suoi meccanismi di elaborazione devono essere specificati nel perseguimento di una teoria completa dell'elaborazione del linguaggio nel cervello.
Tuttavia, i neuroscienziati hanno invece indagato i correlati della composizione del significato che potrebbero non riuscire a catturare o isolare il significato sovra-parola. In una linea di ricerca, i neuroscienziati seguono approcci di neuroimaging classici che consistono nel confrontare una condizione di interesse (ad esempio, sorpresa semantica, frasi complete o frasi errate) con una condizione di controllo (ad esempio, nessuna sorpresa, parole scollegate o frasi corrette). Ad esempio, osservano differenze nelle registrazioni cerebrali durante l'elaborazione di una parola inaspettata rispetto a una prevista in un contesto specifico ( Kutas e Federmeier, 2011 ; Kuperberg et al ., 2003 ; Kuperberg, 2007 ) o un aumento monotono dell'attività neurale nel corso della lettura di una frase ( Fedorenko et al ., 2016 ). Sebbene tali studi siano stati fondamentali per iniziare a studiare i processi alla base della composizione del significato, sosteniamo che i loro risultati siano correlati al processo di integrazione del significato sovra-parola, mentre tralasciano altre componenti chiave, come l'archiviazione e il mantenimento del significato sovra-parola attuale. In un diverso ambito di ricerca, i neuroscienziati costruiscono modelli computazionali del significato attraverso l'incorporamento di parole e frasi tramite l'elaborazione del linguaggio naturale (NLP) (Mitchell et al., 2008; Sudre et al ., 2012 ; Wehbe et al ., 2014b,a; Huth et al ., 2016; Jain e Huth, 2018 ; Toneva e Wehbe, 2019 ; Fyshe et al., 2019 ). Grazie a questi studi, stiamo iniziando a scoprire alcune proprietà della rappresentazione del significato, come il fatto che l'attività neurale associata al significato di una singola parola è distribuita ( Mitchell et al., 2008 ; Huth et al., 2016 ). Tuttavia, i substrati neurali del significato composto e il meccanismo con cui viene rappresentato sono ancora sfuggenti e siamo lontani dal convergere verso una comprensione meccanicistica e algoritmica della composizione del significato che vada oltre le singole parole. Uno dei motivi di queste limitazioni sono le correlazioni di base presenti nel linguaggio naturale, che limitano la capacità dei ricercatori di trarre inferenze scientifiche esatte, poiché mancano i controlli precisi degli esperimenti tradizionali.
In questo lavoro, studiamo la rappresentazione cerebrale del significato sovra-parola utilizzando dati provenienti da letture naturalistiche in due modalità di neuroimaging e integrandoli con una procedura di controllo. Più formalmente, definiamo "significato sovra-parola" come il significato composto di una sequenza di parole che non fa parte del corrispondente "bag-of-words", ovvero il nuovo significato formato combinando una sequenza di parole che non è inclusa nel significato isolato di quelle parole. Oltre al significato implicito, altri esempi di significato sovra-parola includono: 1) un significato contestualizzato specifico di una parola o frase (ad esempio, "banana verde" evoca il significato di una banana acerba, piuttosto che semplicemente di colore verde) che può anche distinguere tra diversi significati della stessa parola (ad esempio, "giocare a un gioco" rispetto a "spettacolo teatrale"), e 2) il diverso significato di due eventi che possono essere descritti con le stesse parole ma con ruoli semantici invertiti (ad esempio, "Giovanni dà una mela a Maria" e "Maria dà una mela a Giovanni").
Abbiamo creato una rappresentazione computerizzata di questo significato sopra-parola, derivata da algoritmi di elaborazione del linguaggio naturale recentemente sviluppati ( Peters et al., 2018 ). Abbiamo scoperto che questa rappresentazione del significato sopra-parola predice l'attività fMRI nelle cortecce temporali anteriore e posteriore, suggerendo che queste aree rappresentino un significato composto. La corteccia temporale posteriore è considerata principalmente una sede per la semantica lessicale (cioè a livello di parola) ( Hagoort, 2020 ; Hickok e Poeppel, 2007 ), quindi la nostra scoperta che mantiene anche il significato sopra-parola suggerisce un substrato comune per la semantica lessicale e combinatoria. Inoltre, abbiamo trovato cluster di voxel sia nel lobo temporale posteriore che in quello anteriore che condividono una rappresentazione comune del significato sopra-parola, suggerendo che le due aree potrebbero collaborare per mantenere il significato sopra-parola. Abbiamo anche scoperto che è molto difficile rilevare la rappresentazione del significato sopra-parola nell'attività MEG. È stato dimostrato che la MEG rivela le firme dei calcoli coinvolti nell'incorporazione di una parola in una frase ( Halgren et al., 2002 ; Lyu et al., 2019 ), che sono a loro volta una funzione del significato composto delle parole osservate finora. Tuttavia, i nostri risultati suggeriscono che la rappresentazione sostenuta del significato composto potrebbe basarsi su meccanismi neurali che non portano a un'attività MEG affidabile. Questa ipotesi richiede una comprensione più approfondita della letteratura sulla composizione del significato e ha importanti implicazioni per il futuro delle interfacce cervello-computer.
Risultati
Controlli computazionali del testo naturale
Abbiamo sfruttato i recenti progressi nell'elaborazione del linguaggio naturale (NLP) che hanno portato alla creazione di algoritmi in grado di catturare il significato delle parole in un contesto specifico. Uno di questi algoritmi è ELMo ( Peters et al., 2018 ), un potente modello linguistico con un'architettura bidirezionale a memoria a lungo termine (LSTM). ELMo stima un embedding contestualizzato per una parola combinando un vettore di input fisso non contestualizzato per quella parola con lo stato interno di un LSTM forward (contenente informazioni sulle parole precedenti) e di un LSTM backward (contenente informazioni sulle parole future). Per catturare informazioni sulla parola t , abbiamo utilizzato il vettore di input per la parola t . Per catturare informazioni sul contesto precedente la parola t , abbiamo utilizzato lo stato interno del LSTM forward calcolato alla parola t – 1 ( Fig. 1B ). Non abbiamo incluso informazioni dal LSTM backward, poiché contiene parole future che non sono ancora state viste al tempo t.

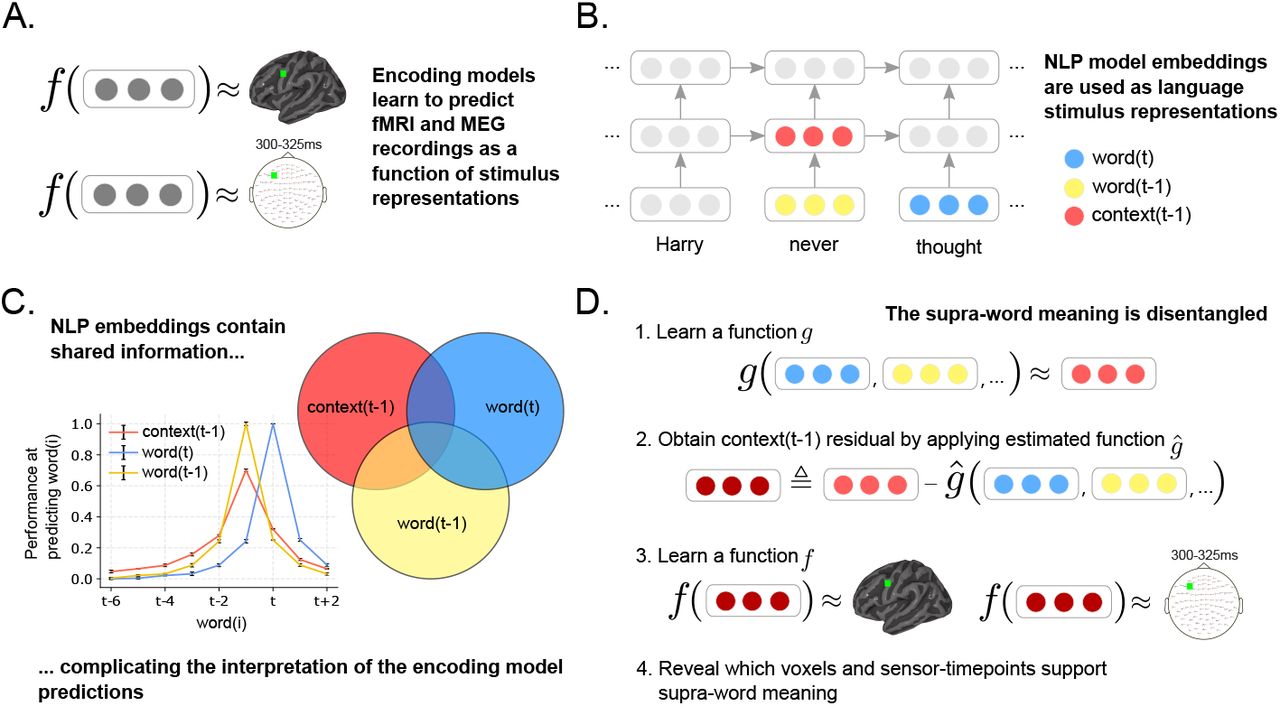
Figura 1:
Approccio. (A) Un modello di codifica f impara a predire una registrazione cerebrale in funzione delle rappresentazioni del testo letto dal partecipante durante l'esperimento. Una funzione diversa viene appresa per ogni voxel in fMRI e per ogni punto temporale del sensore in MEG. (B) Le rappresentazioni degli stimoli sono ottenute da un modello NLP che ha acquisito statistiche linguistiche da milioni di documenti. Questo modello rappresenta le parole utilizzando incorporamenti senza contesto (mostrati in giallo e blu) e incorporamenti di contesto (mostrati in rosso). Gli incorporamenti di contesto sono ottenuti integrando continuamente l'incorporamento senza contesto di ogni nuova parola con l'incorporamento di contesto più recente. (C) L'incorporamento di contesto e di parola condivide informazioni. La prestazione dell'incorporamento di contesto e di parola nel predire le parole nelle posizioni circostanti è tracciata per diverse posizioni. L'incorporamento di contesto contiene informazioni su un massimo di 6 parole passate, mentre l'incorporamento di parola contiene informazioni sugli incorporamenti delle parole circostanti. Per isolare la rappresentazione del significato della parola sovrastante, è necessario tenere conto di queste informazioni condivise. (D) Il significato sopra-parola viene modellato ottenendo le informazioni residue negli embedding contestuali dopo aver rimosso le informazioni relative agli embedding delle parole. Il significato sopra-parola viene utilizzato come input per un modello di codifica f , rivelando quali voxel fMRI e punti temporali del sensore MEG sono modulati dal significato sopra-parola.
Per studiare il significato sovra-parola, il significato che risulta dalla composizione delle parole dovrebbe essere isolato dal significato della singola parola. Gli embedding contestuali di ELMo contengono informazioni sulle singole parole (ad esempio, "finito", "il" e "mela" nel contesto "finito la mela") oltre al significato sovra-parola implicito (ad esempio, mangiare) ( Fig. 1C ). Abbiamo post-elaborato gli embedding contestuali prodotti da ELMo per rimuovere il contributo dovuto ai significati indipendenti dal contesto delle singole parole. Abbiamo costruito un "embedding contestuale residuo" rimuovendo le informazioni condivise tra l'embedding contestuale e i significati delle singole parole ( Fig. 1D ).
Per indagare i substrati neurali e le dinamiche temporali del significato sopra-parola, abbiamo addestrato modelli di codifica, in funzione del significato sopra-parola, per predire le registrazioni cerebrali di nove partecipanti sottoposti a fMRI e otto partecipanti sottoposti a MEG mentre leggevano un capitolo di un libro popolare in rapida presentazione visiva seriale. I modelli di codifica predicono ogni voxel fMRI e punto temporale del sensore MEG, dal testo letto dal partecipante fino a quel momento ( Fig. 1A ). Le prestazioni di predizione di questi modelli sono state testate calcolando la correlazione tra le previsioni del modello e le reali registrazioni cerebrali tenute in evidenza. Sono stati utilizzati test di ipotesi per identificare i voxel fMRI e i punti temporali del sensore MEG che erano significativamente predetti dal significato sopra-parola. Per maggiori dettagli sulla procedura di addestramento e sui test di ipotesi, vedere Materiali e Metodi.
Rilevamento delle regioni previste dal significato sopra-parola
Per identificare le aree cerebrali che rappresentano il significato sovra-parola, ci concentriamo sulla porzione fMRI dell'esperimento. Abbiamo scoperto che molte aree precedentemente implicate nell'elaborazione specifica del linguaggio ( Fedorenko et al., 2010 ; Fedorenko e Thompson-Schill, 2014 ) e nella semantica delle parole ( Binder et al., 2009 ) sono significativamente predette dagli embedding contestuali completi nei soggetti (test di permutazione a livello di voxel, controllo FDR di Benjamini-Hochberg a 0,01 ( Benjamini e Hochberg, 1995 )). Queste aree includono le cortecce temporali bilaterali posteriore e anteriore, gli angulargiri, i giri frontali inferiori, il cingolo posteriore e la corteccia prefrontale dorsomediale ( Fig. 2A e Suppl. Fig. S1 ). Un sottoinsieme di queste aree è anche significativamente predetto dagli embedding contestuali residui. Per quantificare queste osservazioni, selezioniamo le regioni di interesse (ROI) sulla base dei lavori sopra citati ( Fedorenko et al., 2010 ; Binder et al ., 2009), utilizzando maschere ROI completamente indipendenti dalle nostre analisi e dai nostri dati (vedi Materiali e metodi). Gli embedding contestuali completi predicono una proporzione significativa dei voxel all'interno di ciascuna ROI in tutti i 9 partecipanti ( Fig. 2B ; test di Wilcoxon dei ranghi con segno a livello di ROI, p < 0,05, correzione di Holm-Bonferroni ( Holm, 1979 )). Al contrario, gli embedding contestuali residui predicono una proporzione significativa solo dei lobi temporali anteriore e posteriore. Mentre l'embedding contestuale completo è predittivo di gran parte delle registrazioni fMRI in tutto il cervello, il significato sopra-parola è selettivamente predittivo di due regioni del linguaggio: i lobi temporali anteriore (ATL) e posteriore (PTL).

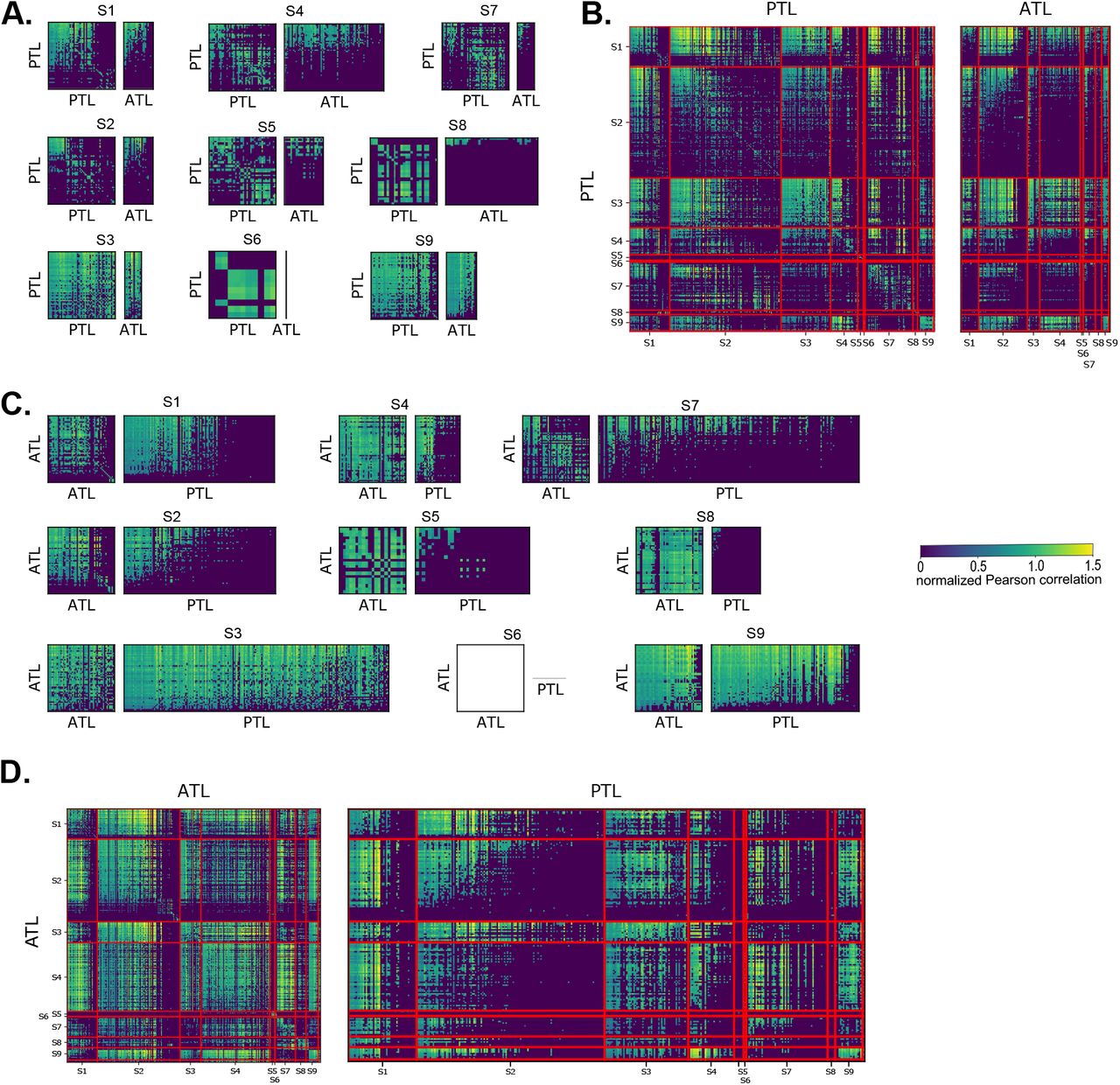
Figura 2:
Risultati fMRI. Visualizzazioni per 4 dei 9 partecipanti con il resto disponibile in Suppl. Fig. S1 – S3 . La significatività a livello di voxel è FDR corretta a α = 0,01. (A) Voxel significativamente predetti da embedding di contesto completo (blu), embedding di contesto residuo (rosso) o entrambi (bianco), visualizzati nello spazio MNI. La maggior parte della corteccia temporale e dell'IFG è predetta da embedding di contesto completo, con embedding di contesto residuo che predicono principalmente un sottoinsieme di quelle aree. (B) Risultati a livello di ROI. (In alto) ROI del sistema linguistico ( Fedorenko et al ., 2010 ) e due ROI semantiche ( Binder et al ., 2009). (In basso) Proporzione di voxel di ROI significativamente predetti da embedding di contesto completo (a sinistra) e da embedding di contesto residuo (a destra). Sono visualizzate le proporzioni mediane di tutti i partecipanti e gli intervalli di confidenza al 95% delle mediane. Il contesto completo prevede tutte le ROI (correzione Holm-Bonferroni a livello di ROI, p < 0,05), mentre il contesto residuo prevede solo ATL e PTL bilaterali. (C) Matrici di generalizzazione spaziale. I modelli addestrati per prevedere i voxel PTL vengono utilizzati per prevedere i voxel PTL e ATL (all'interno del partecipante (sinistra) e tra i partecipanti (destra)). Le correlazioni cross-voxel PTL formano due cluster: i modelli che prevedono l'attività per i voxel in un cluster possono anche prevedere le attività di altri voxel nello stesso cluster, ma non le attività per i voxel nell'altro cluster. Tra i partecipanti, solo uno di questi cluster presenta voxel che prevedono i voxel ATL. (D) Prestazioni dei modelli addestrati sui voxel ATL e PTL nel prevedere l'ATL degli altri partecipanti. Tutti i partecipanti mostrano un cluster di voxel predittivi nel pSTS.
Le parti dell'ATL e del PTL previste dal significato sovra-parola elaborano le stesse informazioni? Ispirandoci alle matrici di generalizzazione temporale ( King e Dehaene, 2014 ), introduciamo matrici di generalizzazione spaziale che stimano la similarità a coppie delle rappresentazioni dei voxel (vedi Materiali e Metodi). Le matrici di generalizzazione spaziale rivelano che il PTL può essere suddiviso in due cluster principali, in modo tale che i modelli dei voxel in un cluster possano predire anche altri voxel in quel cluster, ma non nell'altro cluster ( Fig. 2C e Suppl. Fig. S2 ; test di permutazione a livello di voxel, Benjamini-Hochberg FDR controllato a livello 0,01). Inoltre, i modelli dei voxel all'interno di uno dei cluster PTL, ma non dell'altro, predicono significativamente i voxel nell'ATL. La divisione del PTL in due cluster, uno dei quali è predittivo dell'ATL, può essere osservata all'interno dei partecipanti ( Fig. 2C , a sinistra) e tra i partecipanti ( Fig. 2C , a destra). Al contrario, i voxel ATL mostrano un solo cluster di voxel che sono predittivi sia degli altri voxel ATL sia dei voxel PTL ( Suppl. Fig. S2 ). Questo schema indica che l'organizzazione delle informazioni nell'ATL e in parti del PTL è condivisa e coerente tra i partecipanti. Per localizzare questa rappresentazione condivisa, visualizziamo quanto bene ogni voxel ATL e PTL predice gli ATL degli altri partecipanti ( Fig. 2D e Suppl. Fig. S3 ). I voxel ATL sono predittivi di proporzioni significative dell'ATL tra i partecipanti, rafforzando il singolo cluster di voxel ATL osservato nelle matrici di generalizzazione spaziale. Gran parte del PTL sinistro predice una porzione significativa dell'ATL nei partecipanti, mentre gran parte del PTL destro non lo fa (test di Wilcoxon dei ranghi con segno a livello di ROI, p < 0,05, correzione di Holm-Bonferroni). Il PTL sinistro appare ulteriormente suddiviso, con un cluster di voxel nel solco temporale superiore posteriore (pSTS) che risulta più predittivo. Ciò suggerisce che l'ATL e il pSTS sinistro elaborano un aspetto simile del significato sopra-parola.
L'elaborazione del significato sopra-parola è invisibile in MEG
Per studiare le dinamiche temporali dell'emergenza e della rappresentazione del significato sovra-parola, ci rivolgiamo alla parte MEG dell'esperimento ( Fig. 3 ). Abbiamo calcolato la proporzione di sensori che sono significativamente previsti a diversa granularità spaziale: l'intero cervello ( Fig. 3A ), per suddivisioni dei lobi ( Suppl. Fig. S4 ) e infine in ciascuna posizione di prossimità del sensore ( Fig. 3B ; test di permutazione a livello di punto temporale del sensore, controllo FDR di Benjamini-Hochberg a α = 0,01). L'inclusione del contesto completo è significativamente predittiva delle registrazioni in tutti i lobi ( Fig. 3A , prestazioni visualizzate in colori più chiari; test di Wilcoxon dei ranghi con segno a livello di punto temporale, p < 0,05, correzione FDR di Benjamini-Hochberg). Sorprendentemente, scopriamo che il contesto residuo non prevede significativamente alcun punto temporale nelle registrazioni MEG a nessuna granularità spaziale. Questa sorprendente scoperta porta a due conclusioni. In primo luogo, il significato sovra-parola è invisibile nella MEG. In secondo luogo, ciò che è invece saliente nelle registrazioni MEG sono le informazioni condivise tra il contesto e le singole parole.

Figura 3:
Risultati della previsione MEG a diversa granularità spaziale. Tutti i sottografici presentano la mediana tra i partecipanti e le barre di errore indicano gli intervalli di confidenza al 95% delle mediane. (A) Proporzione di sensori per ciascun punto temporale significativamente predetta dagli embedding completi e residui (visualizzati rispettivamente in colori più chiari e più scuri). La rimozione delle informazioni condivise tra la parola corrente completa, la parola precedente e gli embedding di contesto comporta una significativa riduzione delle prestazioni per tutti gli embedding e i lobi. La riduzione delle prestazioni per l'embedding di contesto (colonna di sinistra) è la più drastica, senza finestre temporali significativamente diverse dalla probabilità per l'embedding di contesto residuo. (B) Proporzioni di vicinanze dei sensori significativamente predette da ciascun embedding residuo. Sono visualizzate solo le proporzioni significative (corrette per FDR, p < 0,05). I residui di contesto non predicono alcuna vicinanza tra i punti temporali dei sensori, mentre sia i residui della parola precedente che quelli della parola corrente predicono un ampio sottoinsieme di punti temporali dei sensori, con picchi di prestazioni nei lobi occipitali e temporali.
Per comprendere l'origine di questa salienza, abbiamo studiato la relazione tra le registrazioni MEG e gli embedding di parole per le parole attualmente lette e quelle lette in precedenza. Un approccio per rivelare questa relazione è quello di addestrare un modello di codifica in funzione dell'embedding di parole ( Jain e Huth, 2018 ; Toneva e Wehbe, 2019 ). Tuttavia, l'embedding di parole corrispondente a una parola in posizione t è correlato con gli embedding di parole circostanti ( Fig. 1C ). Pertanto, parte delle prestazioni di predizione dell'embedding di parole t potrebbe essere dovuta all'elaborazione relativa alle parole precedenti. Per isolare l'elaborazione relativa esclusivamente a una singola parola, abbiamo costruito degli "embedding di parole residui", seguendo l'approccio di costruzione degli embedding di contesto residui (vedi Materiali e Metodi). Osserviamo che gli embedding di parole residui per le parole correnti e precedenti portano a predizioni significativamente peggiori delle registrazioni MEG, se confrontate con i corrispondenti embedding completi ( Fig. 3A , pannelli centrale e destro; test di Wilcoxon con ranghi con segno a livello di punto temporale, p < 0,05, correzione FDR di Benjamini-Hochberg). Ciò indica che una parte significativa dell'attività prevista dagli embedding di parole correnti e precedenti è dovuta alle informazioni condivise con gli embedding di parole circostanti. Ciononostante, scopriamo che l'embedding di parole corrente residuo è ancora significativamente predittivo dell'attività cerebrale ovunque gli embedding completi fossero predittivi. Ciò indica che le proprietà uniche della parola corrente sono ben predittive delle registrazioni MEG a qualsiasi granularità spaziale. L'embedding di parole precedente residuo predice significativamente meno finestre temporali, in particolare 350-500 ms dopo l'inizio della parola. Ciò indica che l'attività nei primi 350 ms quando una parola è sullo schermo è prevista da proprietà uniche della parola precedente. Nel complesso, questi risultati suggeriscono che le proprietà delle parole recenti sono gli elementi predittivi delle registrazioni MEG e che le registrazioni MEG non riflettono il significato delle parole al di là di queste parole recenti.
Infine, abbiamo confrontato direttamente l'efficacia con cui ciascuna modalità di imaging può essere predetta da ciascun embedding di significato ( Fig. 4 ). Gli embedding residui predicono fMRI e MEG con un'accuratezza significativamente diversa ( Fig. 4A ), con fMRI significativamente meglio predetta rispetto a MEG dal contesto residuo e MEG significativamente meglio predetta dal residuo delle parole precedenti e attuali (test di Wilcoxon della somma dei ranghi, p < 0,05, correzione di Holm-Bonferroni). Al contrario, gli embedding di contesto completi non mostrano una differenza significativa nella previsione delle registrazioni fMRI e MEG ( Fig. 4B ). Osserviamo inoltre che gli embedding residui portano a un modello opposto di previsione nelle due modalità ( Fig. 4C ). Mentre il contesto residuo predice meglio l'fMRI tra i tre incorporamenti residui, ha le prestazioni peggiori tra i tre nel predire la MEG (test di Wilcoxon con ranghi con segno, p < 0,05, correzione di Holm-Bonferroni). Al contrario, il contesto completo e gli incorporamenti di parole precedenti non mostrano una differenza significativa nella previsione MEG ( Fig. 4D ), suggerendo che è la rimozione delle informazioni sulle singole parole dall'incorporamento del contesto a portare a una previsione MEG significativamente peggiore. Questi risultati suggeriscono inoltre che fMRI e MEG riflettono aspetti diversi dell'elaborazione del linguaggio: mentre le registrazioni MEG riflettono l'elaborazione relativa al contesto recente, le registrazioni fMRI catturano il significato contestuale che va oltre il significato delle singole parole.

Figura 4:
Confronti diretti delle prestazioni di predizione di diversi incorporamenti di significato. Sono mostrate le proporzioni mediane tra i partecipanti e gli intervalli di confidenza al 95% delle mediane. Le differenze tra le modalità sono testate per la significatività utilizzando un test di Wilcoxon delle somme dei ranghi. Le differenze all'interno della modalità sono testate utilizzando un test di Wilcoxon dei ranghi con segno. Tutti i valori p sono aggiustati per confronti multipli con la procedura di Holm-Bonferroni ad α = 0,05. (A) Gli incorporamenti residui di parola precedente, contesto e parola attuale predicono fMRI e MEG con differenze significative. (B) Gli incorporamenti di contesto completi non predicono fMRI e MEG con differenze significative, mentre gli incorporamenti completi di parola attuale e parola precedente predicono MEG significativamente meglio di fMRI. (C) MEG e fMRI mostrano un modello contrastante di predizione da parte degli incorporamenti residui. Il residuo di parola attuale predice meglio l'attività MEG, significativamente meglio del residuo di parola precedente, che a sua volta predice MEG significativamente più del residuo di contesto. Al contrario, i residui di contesto predicono significativamente l'attività fMRI meglio dei residui di parola precedenti e attuali. (D) Gli embedding completi di parola precedente e contesto non predicono la MEG in modo significativamente diverso. (E) Tutti gli embedding completi predicono sia fMRI che MEG significativamente meglio dei corrispondenti embedding residui.
Discussione
Abbiamo reso possibile l'indagine del significato multi-parola emergente, o significato sovra-parola, nel cervello ideando una sua rappresentazione computazionale che combina rappresentazioni di testo naturale ottenute da recenti algoritmi di reti neurali con un controllo computazionale che distingue il significato composto da quello delle singole parole. Abbiamo studiato le firme di elaborazione spaziale e temporale del significato sovra-parola valutandone la capacità di predire posizioni e punti temporali specifici dell'attività cerebrale registrata rispettivamente tramite fMRI e MEG.
Abbiamo scoperto che la rappresentazione del significato sopra-parola da noi ideata predice le registrazioni fMRI nei lobi temporali anteriore e posteriore bilaterali (ATL e PTL). Questa scoperta supporta alcune ipotesi attuali sulla composizione del linguaggio in letteratura. In particolare, i nostri risultati forniscono nuove prove del fatto che l'ATL elabora il significato composto al di là dei semplici concetti concreti, il che supporta l'ipotesi che l'ATL sia un centro di integrazione semantica (Visser et al., 2010; Pallier et al ., 2011 ; Pylkkänen, 2020 ). I nostri risultati potrebbero anche allinearsi con l'ipotesi che il solco temporale postero-superiore (pSTS, parte del PTL) sia coinvolto nella costruzione di un tipo di significato sopra-parola, integrando le informazioni sul verbo e i suoi argomenti con altre informazioni sintattiche ( Friederici, 2011 ; Frankland e Greene, 2015 ; Skeide e Friederici, 2016 ). Inoltre, i nostri risultati pongono interrogativi sulla teoria che postula il PTL sinistro come sede primaria di semantica lessicale (ovvero a livello di parola) e l'IFG sinistro come centro di informazioni contestuali integrate ( Hagoort, 2020 ). Pone inoltre interrogativi sulla teoria secondo cui la semantica combinatoria viene elaborata nell'ATL mentre la semantica lessicale viene elaborata in regioni più posteriori ( Hickok e Poeppel, 2007 ). La nostra scoperta che il PTL mantiene il significato sopra-parola indica che il ruolo del PTL si estende oltre la semantica a livello di parola e suggerisce un substrato comune per la semantica lessicale e combinatoria. Inoltre, non troviamo prove di significato sopra-parola nell'IFG sinistro, sebbene ciò non dimostri che l'IFG sinistro non rappresenti il significato sopra-parola: la mancanza di significatività potrebbe essere dovuta alla bassa potenza statistica. Infine, la scoperta che i cluster di voxel nel PTL e nell'ATL condividono una rappresentazione comune del significato composto suggerisce che le due aree potrebbero collaborare per mantenere il significato sopra-parola.
Sorprendentemente, abbiamo scoperto che, sebbene la nostra rappresentazione sopra-significato prevedesse una proporzione significativa di voxel fMRI, non prevedeva significativamente alcun punto temporale del sensore nella MEG. Al contrario, le registrazioni MEG erano significativamente predette da informazioni uniche sia per le parole attualmente lette che per quelle precedentemente lette. Questi risultati suggeriscono una differenza nei processi cerebrali sottostanti catturati da fMRI e MEG. Infatti, sebbene sia ampiamente noto che le registrazioni fMRI e MEG derivino da segnali fisiologici diversi, se catturino gli stessi processi cerebrali sottostanti è ancora oggetto di dibattito ( Hall et al., 2014 ). I nostri risultati suggeriscono che le registrazioni fMRI sono sensibili al significato sopra-parola, mentre le registrazioni MEG riflettono processi istantanei relativi sia alla parola attualmente letta che a quella precedentemente letta. Un probabile candidato per il processo istantaneo riflesso nella MEG è il processo di integrazione della parola attuale con il contesto precedente. La sensibilità alla parola precedentemente letta ha molte possibili spiegazioni. Una possibile spiegazione è che una parola potrebbe richiedere più tempo per essere elaborata e integrata nel significato composto rispetto alla durata della sua permanenza sullo schermo. Un'altra possibile spiegazione è che una parola possa limitare l'elaborazione della parola che la segue, evidenziandone le proprietà rilevanti e facilitandone la composizione. L'ipotesi che le registrazioni MEG riflettano il processo di composizione si allinea bene con un vasto numero di precedenti risultati che caratterizzano risposte transitorie evocate da uno stimolo difficile da integrare con il contesto precedente ( Kutas e Federmeier, 2011 ; Kuperberg et al., 2003 ; Kuperberg, 2007 ) e con risultati che mostrano che le registrazioni MEG sono meglio adattate a un modello vincolato dal significato delle parole immediatamente precedenti ( Lyu et al ., 2019). In effetti, i nostri risultati non sono in disaccordo con questa letteratura: non dimostrano che l'attività MEG non riveli processi di integrazione delle parole che dipendono dal contesto precedente. Piuttosto, i nostri risultati suggeriscono che la rappresentazione di quel contesto precedente non è visibile nella MEG.
La differenza osservata nella previsione delle registrazioni fMRI e MEG solleva l'ipotesi che il processo di mantenimento del significato composto non si basi su meccanismi neurali che si ritiene generino il segnale MEG (come il flusso di corrente sincronizzato nei dendriti delle cellule piramidali ( Hall et al ., 2014 )), ma su altri meccanismi non visibili nel segnale MEG o che potrebbero essere indistinguibili dal rumore (ad esempio, scariche neurali non sincronizzate), ma che hanno sufficienti richieste metaboliche per generare una risposta BOLD. Possibili spiegazioni alternative per la mancanza di prevedibilità della MEG da parte del significato sopra-parola sono che la rappresentazione del significato sopra-parola potrebbe essere troppo distribuita per essere catturata dalla MEG a causa della sua scarsa risoluzione spaziale. Tuttavia, osserviamo che il significato sopra-parola predice circa il 5-10% di tutti i voxel fMRI corticali nei partecipanti, per lo più centrati nell'ATL e nel PTL. Pertanto, è improbabile che nessun punto temporale del sensore MEG sia sensibile a questo segnale se è rilevabile nelle variazioni del campo magnetico. Inoltre, è noto che la MEG è sensibile all'attività neurale che ha origine nei solchi e, poiché abbiamo scoperto che i voxel sensibili al significato sovra-parola si trovano nei solchi, questa spiegazione è ancora meno probabile. Questi risultati richiedono una comprensione più approfondita di lavori precedenti che mirano a studiare la composizione del significato a livello di frase utilizzando la MEG, nonché possibilmente altri tipi di modalità di imaging che si basano su attivazione sincronizzata, come EEG ed ECoG. I nostri risultati suggeriscono che gli aumenti osservati nell'attività misurata da queste modalità durante la lettura di frasi (Fedorenko et al., 2016; Hultén et al ., 2019 ) e il miglioramento dell'adattamento da parte di un modello vincolato da un contesto molto recente (Lyu et al., 2019) potrebbero essere dovuti a processi di integrazione istantanea piuttosto che al significato a livello di frase. Sono necessari studi futuri per capire se e come queste modalità di imaging possano essere utilizzate per studiare il significato a livello di frase.
La nostra analisi dipende dal grado in cui la rete neurale computazionale che abbiamo scelto è in grado di rappresentare il significato composto. Sulla base delle prestazioni competitive di ELMo nei compiti downstream ( Peters et al ., 2018) e della capacità di catturare strutture linguistiche complesse ( Tenney et al ., 2019 ), riteniamo che ELMo sia in grado di estrarre alcuni aspetti del significato composto. Il grado in cui questo significato composto riflette quello nel cervello è una questione importante che abbiamo appena iniziato a studiare e che necessita di ulteriori approfondimenti. In secondo luogo, il nostro approccio residuale tiene conto solo della dipendenza lineare tra i singoli word embedding e i context embedding. Per costruzione, lo stato interno dell'LSTM in ELMo contiene dipendenze non lineari dal vettore di parole in input e dallo stato LSTM precedente. È possibile, tuttavia, che alcune dimensioni dello stato interno dell'ELMo LSTM corrispondano a operazioni non lineari sulle dimensioni del solo vettore di input, senza un contributo dal precedente stato interno dell'LSTM (vedere Materiali e metodi per le equazioni dell'LSTM). Questa trasformazione non lineare della parola in input potrebbe non essere rimossa dalla nostra procedura residua e se sia in linea con l'elaborazione delle singole parole nel cervello è una questione che sarà oggetto di ricerca futura.
La sorprendente scoperta che il significato sovra-parola sia difficile da catturare utilizzando la MEG ha implicazioni per la futura ricerca e applicazione nel campo della neuroimmagine in cui il linguaggio naturale viene decodificato dal cervello. Sebbene un'elevata risoluzione temporale dell'imaging sia fondamentale per raggiungere un livello meccanicistico di comprensione dell'elaborazione del linguaggio, i nostri risultati suggeriscono che potrebbe essere necessaria una modalità diversa dalla MEG per rilevare informazioni contestuali a lungo raggio. Inoltre, il fatto che un aspetto del significato possa essere predittivo in una modalità di imaging e invisibile nell'altra richiede cautela nell'interpretazione dei risultati sul cervello ottenuti da una sola modalità, poiché alcune parti del puzzle sono sistematicamente nascoste. I nostri risultati suggeriscono anche che la modalità di imaging può influire sulla capacità di decodificare il significato contestualizzato delle parole, che è fondamentale per le interfacce cervello-computer (BCI) che mirano a decodificare il parlato. Il recente successo nella decodifica del parlato da registrazioni ECoG ( Makin et al ., 2020 ) è promettente, ma deve essere valutato attentamente con stimoli più diversificati e naturalistici. L'utilizzo dell'interconnessione tra parole (BCI) per decodificare il parlato nella vita reale è complicato dall'incertezza intrinseca nella decodifica di ogni parola e dal fatto che lo spazio di tutte le possibili espressioni non è limitato. Resta ancora da stabilire se le informazioni a livello di parola trasmesse dall'elettrofisiologia saranno sufficienti a decodificare l'intento di una persona o se la mancanza di significato al di sopra della parola debba essere compensata in altri modi.
Materiali e metodi
Dati fMRI e pre-elaborazione
Utilizziamo i dati fMRI di 9 partecipanti che leggono il capitolo 9 di Harry Potter e la pietra filosofale ( Rowling, 2012 ), raccolti e resi disponibili online da Wehbe et al. (2014b) . Le parole sono state presentate una alla volta a una velocità di 0,5 secondi ciascuna. I dati fMRI sono stati acquisiti a una velocità di 2 secondi per immagine, ovvero il tempo di ripetizione (TR) è di 2 secondi. Le immagini erano composte da voxel di 3 × 3 × 3 mm. I dati per ciascun partecipante sono stati corretti in termini di tempo di fetta e movimento utilizzando SPM8 ( Kay et al., 2008 ), quindi detrended e smoothed con un kernel full-width-half-max di 3 mm. La superficie cerebrale di ciascun partecipante è stata ricostruita utilizzando Freesurfer ( Fischl, 2012 ) ed è stata ottenuta una maschera di materia grigia. Per gestire e rappresentare graficamente i dati è stato utilizzato il software Pycortex ( Gao et al ., 2015 ). Per ogni partecipante sono stati conservati 25.000-31.000 voxel corticali.
Dati MEG e pre-elaborazione
Lo stesso paradigma è stato registrato per 8 partecipanti utilizzando la MEG dagli autori di (Wehbe et al., 2014a) e condiviso su nostra richiesta. Questi dati sono stati registrati su 306 sensori organizzati in 102 posizioni attorno alla testa. La MEG registra la variazione del campo magnetico dovuta all'attività neuronale e i dati che abbiamo utilizzato sono stati campionati a 1 kHz, quindi preelaborati utilizzando il metodo Signal Space Separation (SSS) ( Taulu et al ., 2004 ) e la sua estensione temporale (tSSS) ( Taulu e Simola, 2006 ). Il segnale in ogni sensore è stato sottocampionato in intervalli di tempo non sovrapposti di 25 ms. Per ciascuna delle 5176 parole del capitolo, abbiamo quindi ottenuto una registrazione per 306 sensori a 20 punti temporali dall'inizio della parola (poiché ogni parola è stata presentata per 500 ms).
Dettagli ELMo
A ogni livello, per ogni parola, ELMo combina le rappresentazioni interne di due LSTM indipendenti: una LSTM forward (contenente informazioni sulle parole precedenti) e una LSTM backward (contenente informazioni sulle parole future). Abbiamo estratto gli embedding di contesto solo dalla LSTM forward per abbinare più accuratamente i partecipanti che non hanno visto le parole future. Per un token di parola t, la LSTM forward genera la rappresentazione nascosta.nello strato l utilizzando le seguenti equazioni di aggiornamento:

dove b c e w c rappresentano la polarizzazione e il peso appresi, e f t , o t , e i t rappresentano le porte di dimenticanza, di uscita e di ingresso. Gli stati delle porte sono calcolati secondo le seguenti equazioni:

dove σ ( x ) rappresenta la funzione sigmoide e bx e wx rappresentano il bias e il peso appresi della porta corrispondente. I parametri appresi vengono addestrati per predire l'identità di una parola data una serie di parole precedenti, in un corpus di testo di grandi dimensioni. Utilizziamo una versione pre-addestrata di ELMo con 2 livelli LSTM nascosti fornita da Gardner et al. (2018) .
Ottenere rappresentazioni complete dello stimolo
Otteniamo un word embedding ELMo completo (in contrapposizione a un word embedding residuo) per la parola w n passando la parola w n attraverso il modello ELMo preaddestrato e ottenendo gli embedding a livello di token (ovvero dal livello 0) per w n . Se la parola w n contiene più token, calcoliamo la media degli embedding a livello di token corrispondenti e utilizziamo questa media come word embedding completo finale. Otteniamo un context embedding ELMo completo per la parola w n passando le 25 parole più recenti ( w n -24 , …, w n ) attraverso il modello ELMo preaddestrato e ottenendo gli embedding dal primo livello nascosto (ovvero dal livello 1) del forward LSTM per w n . Se la parola w n contiene più token, calcoliamo la media degli embedding di livello 1 corrispondenti e utilizziamo questa media come context embedding completo finale per la parola w n . Utilizziamo 25 parole per estrarre l'incorporamento del contesto perché è stato precedentemente dimostrato che ELMo e altri LSTM sembrano ridurre la quantità di informazioni che mantengono oltre le 20-25 parole nel passato ( Khandelwal et al ., 2018 ; Toneva e Wehbe, 2019 ).
Ottenere rappresentazioni di stimoli residui
Otteniamo tre tipi di incorporamenti residui per ogni parola in posizione t nell'insieme degli stimoli: 1) incorporamento del contesto residuo (t-1), 2) incorporamento della parola residua ( t -1) e 3) incorporamento della parola residua (t). Calcoliamo tutti e tre i tipi utilizzando lo stesso approccio generale di addestramento di una regressione lineare regolarizzata, ma con input x t e output y t che cambiano a seconda del tipo di incorporamento residuo. I passaggi per l'approccio generale sono i seguenti, dati un input x t e un output y t :
Fase 1: Apprendiamo una funzione lineare g che predice ogni dimensione di y t come combinazione lineare di x t . Seguiamo gli stessi passaggi descritti nell'addestramento della funzione f nel modello di codifica. In particolare, modelliamo g come una funzione lineare, regolarizzata dalla penalità di cresta. Il modello viene addestrato tramite convalida incrociata quadrupla e il parametro di regolarizzazione viene scelto tramite convalida incrociata annidata.
Fase 2: Ottenere il residuo, utilizzando la stima della funzione g appresa in precedenza. Questa è la rappresentazione finale dello stimolo residuo.
Per l'embedding del contesto residuo (t-1), l'input x t è la concatenazione degli embedding di parola completi per le 25 parole consecutive w t -24 , …, w t e l'output y t è l'embedding del contesto completo (t-1). Per gli embedding di parola residui ( t -1), l'input x t è la concatenazione dell'embedding del contesto completo ( t -1) e degli embedding di parola completi per le 24 parole consecutive w t -24 , …, w t che escludono l'embedding di parola completo per parola (t-1) e l'output y t è l'embedding di parola completo (t-1). Per gli embedding di parole residue ( t ), l'input x t è la concatenazione dell'embedding di contesto completo ( t -1) e degli embedding di parole completi per le 24 parole consecutive w t -24 , …, w t -1 e l'output y t è l'embedding di parole completo (t).
Valutazione del modello di codifica
Valutiamo le previsioni di ciascun modello di codifica calcolando la correlazione di Pearson tra le registrazioni cerebrali trattenute e le corrispondenti previsioni nel contesto di convalida incrociata a quattro livelli. Calcoliamo un valore di correlazione per ciascuno dei quattro livelli di convalida incrociata e riportiamo il valore medio come prestazione finale del modello di codifica.
Formazione generale del modello di codifica
Per ogni tipo di embedding et , stimiamo un modello di codifica che prende et come input e predice la registrazione cerebrale associata alla lettura delle stesse parole utilizzate per derivare et . Stimiamo una funzione f , tale che f ( et ) = b , dove b è l'attività cerebrale registrata con MEG o fMRI. Seguiamo lavori precedenti ( Surre et al ., 2012 ; Wehbe et al., 2014b,a; Nishimoto et al., 2011; Huth et al ., 2016) e modelliamo f come una funzione lineare, regolarizzata dalla penalità di cresta. Il modello viene addestrato tramite convalida incrociata quadrupla e il parametro di regolarizzazione viene scelto tramite convalida incrociata annidata.
Modelli di codifica fMRI
La regolarizzazione di Ridge viene utilizzata per stimare i parametri di un modello lineare che predice l'attività cerebrale y i in ogni voxel fMRI i come combinazione lineare di un particolare embedding NLP x . Per ogni dimensione di output (voxel), il parametro di regolarizzazione di Ridge viene scelto indipendentemente tramite convalida incrociata annidata. Utilizziamo la regressione di Ridge per la sua efficienza computazionale e per i risultati di Wehbe et al. (2015) che mostrano che per i dati fMRI, purché venga utilizzata una regolarizzazione appropriata e il parametro di regolarizzazione venga scelto tramite convalida incrociata per ciascun voxel in modo indipendente, diverse tecniche di regolarizzazione portano a risultati simili. In effetti, la regressione di Ridge è una tecnica di regolarizzazione comune utilizzata per costruire fMRI predittive ( Mitchell et al ., 2008; Nishimoto et al ., 2011; Wehbe et al ., 2014b; Huth et al ., 2016).
Per ogni voxel i , un modello è adatto a predire i segnali, dove n è il numero di punti temporali, in funzione dell'embedding NLP. Le parole presentate ai partecipanti vengono prima raggruppate in base all'intervallo TR in cui sono state presentate. Quindi, l'embedding NLP delle parole in ogni gruppo viene mediato per formare una sequenza di caratteristiche x = [ x 4 , x 2 ,…, x n ] che sono allineate con i segnali cerebrali. I modelli vengono addestrati a predire il segnale al tempo t, y t , utilizzando il vettore concatenato z t formato da [ x t -1 , x t -2 , x t -3 , x t -4 ]. Le caratteristiche delle parole presentate nei volumi precedenti sono incluse per tenere conto del ritardo nella risposta emodinamica registrata dalla fMRI. In effetti, la risposta misurata dalla fMRI è una conseguenza indiretta dell'attività cerebrale che raggiunge il picco circa 6 secondi dopo l'inizio dello stimolo, e la soluzione di esprimere l'attività cerebrale in funzione delle caratteristiche dei punti temporali precedenti è una soluzione comune per costruire modelli predittivi ( Nishimoto et al ., 2011 ; Wehbe et al ., 2014b; Huth et al ., 2016).
Per ogni partecipante e per ogni incorporamento NLP, eseguiamo una procedura di convalida incrociata per stimare quanto l'incorporamento NLP sia predittivo dell'attività cerebrale in ogni voxel i . Per ogni piega:
I dati fMRI Y e la matrice delle caratteristiche Z = z 4 , z 2 ,... z n sono suddivisi nelle corrispondenti matrici di addestramento e di convalida. Queste matrici sono normalizzate individualmente (media pari a 0 e deviazione standard pari a 1 per ciascun voxel nel tempo), terminando con le matrici di addestramento Y R e Z R e le matrici di convalida Y V e Z V .
Utilizzando la piega del treno, un modello w i viene stimato come:
Per prima cosa viene utilizzata una procedura di convalida incrociata annidata a dieci livelli per identificare il miglior λ i per ogni voxel i che minimizzi l'errore di convalida incrociata annidata. w i viene quindi stimato utilizzando λ i sull'intero livello di addestramento.
Le previsioni per ciascun voxel sulla piega di convalida sono ottenute come p = Z V w i .

I passaggi sopra descritti vengono ripetuti per ciascuna delle quattro pieghe di convalida incrociata e si ottiene una correlazione media per ciascun voxel i , incorporamento NLP e partecipante.
Modelli di codifica MEG
I dati MEG vengono campionati più velocemente della velocità di presentazione delle parole, quindi per ogni parola abbiamo 20 volte i punti registrati su 306 sensori. La regolarizzazione Ridge viene utilizzata in modo simile per stimare i parametri di un modello lineare che predice l'attività cerebrale y i,τ in ogni sensore MEG i al tempo τ dopo l'inizio della parola. Per ogni dimensione di output (tupla sensore/tempo i,τ ), il parametro di regolarizzazione Ridge viene scelto in modo indipendente tramite convalida incrociata annidata.
Per ogni tupla i, τ , un modello è adatto a predire i segnali, dove n è il numero di parole nella storia, in funzione degli embedding NLP. Utilizziamo come input il vettore di parole x senza i ritardi utilizzati nella risonanza magnetica funzionale, poiché le registrazioni MEG catturano le conseguenze istantanee dell'attività cerebrale (variazione del campo magnetico). I modelli sono addestrati a predire il segnale al momento della parola., utilizzando il vettore x t .
Per ogni partecipante e per ogni incorporamento NLP, eseguiamo una procedura di convalida incrociata per stimare quanto sia predittivo l'incorporamento NLP dell'attività cerebrale in ogni punto temporale del sensore i . Per ogni piega:
I dati MEG Y e la matrice delle caratteristiche X = x 4 , x 2 , … x n vengono suddivisi nelle corrispondenti matrici di addestramento e di convalida e queste matrici vengono normalizzate individualmente (per ottenere una media di 0 e una deviazione standard di 1 per ciascun voxel nel tempo), terminando con le matrici di addestramento Y R e X R e le matrici di convalida Y V e Z V .
Utilizzando la piega del treno, un modello w ( i,τ ) viene stimato come:
Per prima cosa viene utilizzata una procedura di convalida incrociata annidata a dieci livelli per identificare il miglior λ ( i,τ) per ogni sensore, tupla di punti temporali ( i,τ) che minimizzi l'errore di convalida incrociata annidata. w ( i,τ ) ℓ viene quindi stimato utilizzando λ ( i,τ ) sull'intera piega di addestramento.
Le previsioni per ogni sensore, tupla di punti temporali ( i,τ ) sulla piega di convalida sono ottenute come p = X V w ( i,τ ) .

I passaggi precedenti vengono ripetuti per ciascuna delle quattro pieghe di convalida incrociata e si ottiene una correlazione media per ogni posizione del sensore, tupla di punti temporali ( s,τ ), ogni incorporamento NLP e ogni partecipante.
Matrici di generalizzazione spaziale
Introduciamo il concetto di matrici di generalizzazione spaziale, che verifica se un modello di codifica addestrato per predire un particolare voxel può essere generalizzato per predire altri voxel. Questo approccio può essere applicato ai voxel all'interno dello stesso partecipante o di altri partecipanti. Lo scopo di questo metodo è verificare se due voxel si relazionano a una specifica rappresentazione dell'input (ad esempio, l'incorporamento NLP) in modo simile. Se un modello di codifica per un particolare voxel è in grado di predire significativamente l'attività di un altro voxel, concludiamo che i due voxel elaborano informazioni simili rispetto all'input del modello di codifica.
Per ogni coppia di voxel ( i,j ), seguiamo innanzitutto il nostro approccio generale di addestramento di un modello di codifica per predire il voxel i in funzione di una specifica rappresentazione dello stimolo, descritto sopra, e testiamo quanto bene le previsioni del modello di codifica siano correlate con l'attività del voxel j . Eseguiamo questo per tutte le coppie di voxel nel PTL e nell'ATL in tutti i 9 partecipanti. Infine, normalizziamo la prestazione risultante nella previsione del voxel j dividendola per la prestazione nella previsione dei dati di test dal voxel i , che è stata mantenuta durante il processo di addestramento. La significatività della prestazione del modello di codifica sul voxel j viene valutata utilizzando un test di permutazione, descritto di seguito.
Test di permutazione
La significatività del grado di previsione di un singolo voxel o di un punto temporale del sensore viene valutata sulla base di un test di permutazione standard. Per condurre il test di permutazione, permutiamo a blocchi le previsioni di uno specifico modello di codifica all'interno di ciascuna delle quattro sessioni di convalida incrociata e calcoliamo la correlazione tra le previsioni permutate a blocchi e i corrispondenti valori veri del voxel/punto temporale del sensore. Utilizziamo blocchi di 5TR in fMRI (corrispondenti a 20 parole presentate) e 20 parole in MEG per mantenere parte della struttura autoregressiva nelle registrazioni cerebrali permutate. Eseguiamo 1000 permutazioni e calcoliamo il numero di volte in cui la correlazione media risultante attraverso le quattro fasi di convalida incrociata delle previsioni permutate è superiore alla correlazione media delle previsioni originali non permutate. I valori p risultanti per tutti i voxel/punti temporali del sensore/finestre temporali sono corretti FDR per confronti multipli utilizzando la procedura Benjamini-Hochberg ( Benjamini e Hochberg, 1995 ).
Proporzioni casuali di ROI/finestre temporali previste in modo significativo
Per stabilire se una proporzione significativa di una ROI/finestra temporale sia prevista da uno specifico modello di codifica, confrontiamo la proporzione della ROI/finestra temporale che è spiegata in modo significativo dal modello di codifica con una proporzione della ROI/finestra temporale che è spiegata in modo significativo dal caso. Eseguiamo questo test per tutte le proporzioni della stessa ROI/finestra temporale tra i partecipanti, utilizzando un test di Wilcoxon con ranghi con segno. Calcoliamo la proporzione di una ROI/finestra temporale che è prevista in modo significativo dal caso utilizzando i test di permutazione descritti sopra. Per ogni permutazione k , calcoliamo il valore p di ciascun voxel in questa permutazione in base alla sua performance rispetto alle altre permutazioni. Successivamente, per ogni ROI/finestra temporale, calcoliamo la proporzione di questa ROI/finestra temporale con valori p < 0,01 dopo la correzione FDR, per ogni permutazione. La proporzione casuale finale di una ROI/finestra temporale per uno specifico modello di codifica e partecipante è la proporzione casuale media tra le permutazioni.
Intervalli di confidenza
Utilizziamo un pacchetto open source ( Sheppard et al ., 2020 ) per calcolare gli intervalli di confidenza corretti per il bias al 95% delle proporzioni mediane tra i partecipanti. Utilizziamo intervalli di confidenza corretti per il bias ( Efron e Tibshirani, 1994 ) per tenere conto di qualsiasi possibile bias nella mediana del campione dovuto a una dimensione campionaria ridotta o a una distribuzione asimmetrica ( Miller, 1988 ).
Esperimenti che rivelano informazioni condivise tra gli embedding NLP
Per ciascuno dei 3 tipi di incorporamento NLP (ovvero incorporamento context(t-1), incorporamento word(t-1), incorporamento word(t)), addestriamo un modello di codifica prendendo come input ogni incorporamento NLP e prevedendo come output l'incorporamento word per word( i ), dove i ∈ [ t – 6, t + 2]. Valutiamo le previsioni dei modelli di codifica utilizzando la correlazione di Pearson e otteniamo una correlazione media sui quattro livelli di convalida incrociata.
Contributi degli autori
LW e TM hanno selezionato gli stimoli sperimentali. LW ha raccolto i dati fMRI e MEG. Tutti gli autori hanno contribuito a concepire e progettare le analisi sperimentali e ad analizzare i dati. MT ha sviluppato la tecnica per rimuovere le informazioni condivise negli embedding delle reti neurali e ha condotto le analisi successive. MT e LW hanno scritto la bozza originale del manoscritto. Tutti gli autori hanno contribuito alla revisione e all'editing.
Interessi in competizione
Gli autori dichiarano di non avere conflitti di interesse.
Informazioni supplementari per

Figura S1:
Visualizzazione qualitativa dei voxel che sono significativamente predetti dalla rappresentazione contestualizzata completa (in blu), dalla rappresentazione contestualizzata residua (in rosso) o da entrambe (in bianco). Un voxel viene determinato come significativamente predetto tramite un test di permutazione e una correzione FDR per confronti multipli al livello 0,01. Ampie parti del sistema linguistico, che si estendono dalla corteccia temporale alla corteccia frontale inferiore, sono significativamente predette dagli embedding contestuali completi. I voxel significativamente predetti dal residuo di contesto sono in gran parte un sottoinsieme di quelli predetti dagli embedding contestuali completi.

Figura S2:
Matrici di generalizzazione spaziale per tutti i 9 partecipanti. I modelli addestrati per predire i voxel PTL vengono utilizzati per predire i voxel PTL e ATL (all'interno del partecipante ( A ) e tra i partecipanti ( B )). I modelli addestrati per predire i voxel ATL vengono utilizzati per predire i voxel ATL e PTL (all'interno del partecipante ( C ) e tra i partecipanti ( D )). Si noti che le matrici diagonali a blocchi delle correlazioni tra i partecipanti (in B/D ) sono equivalenti ai grafici in A/C . Solo i voxel che sono significativamente previsti dal residuo di contesto sono inclusi in questa analisi. Si noti che il partecipante S6 non ha voxel significativamente previsti nell'ATL. Le correlazioni vengono normalizzate dividendo la prestazione di un modello addestrato sul voxel i nel predire il voxel target j per la prestazione di un modello addestrato sul voxel target j. Le correlazioni cross-voxel PTL formano due cluster: i voxel di un cluster possono predire l'uno l'altro, ma non i voxel dell'altro cluster. Tra i partecipanti, solo uno di questi cluster presenta voxel che predicono i voxel ATL.

Figura S3:
Prestazioni dei modelli di codifica addestrati sui voxel ATL e PTL nel predire l'ATL degli altri partecipanti per i restanti 5 partecipanti. Tutti i partecipanti che hanno più di qualche voxel significativamente predetto (6 su 9 partecipanti) mostrano un cluster di voxel predittivi nel pSTS.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Figura S4:
Proporzioni di sensori MEG significativamente previsti per ciascun punto temporale, divisi per lobo. Tutti i sottografici presentano la mediana tra i partecipanti e le barre di errore indicano gli intervalli di confidenza al 95% delle mediane. Le prestazioni degli embedding residui vengono confrontate con quelle degli embedding completi (rispettivamente colori più scuri e più chiari, corretti per FDR, p < 0,05). La rimozione delle informazioni condivise tra la parola corrente completa, la parola precedente e gli embedding contestuali si traduce in una significativa riduzione delle prestazioni per tutti gli embedding e i lobi. La riduzione delle prestazioni per l'embedding contestuale (colonna di sinistra) è la più drastica, senza finestre temporali significative per l'embedding contestuale residuo tra i lobi.
Ringraziamenti
Gli autori ringraziano Erika Laing e Daniel Howarth per l'aiuto nella raccolta e pre-elaborazione dei dati, e Michael J. Tarr per il prezioso feedback sul manoscritto. Questa ricerca è stata in parte supportata da fondi di avviamento del Dipartimento di Apprendimento Automatico della Carnegie Mellon University, dal Google Faculty Research Award e dall'Air Force Office of Scientific Research attraverso le sovvenzioni di ricerca FA95501710218 e FA95502010118.
Note a piè di pagina
Titolo e Abstract rivisti; Figura 3 rivista; Figura S4 aggiunta al Supplementare;
Riferimenti
↵Benjamini , Y. e Hochberg , Y. ( 1995 ). Controllo del tasso di false scoperte: un approccio pratico e potente ai test multipli .Journalof the Royal statistical society: serie B (Metodologica) , 57 ( 1 ), 289-300 .CrossRefPubMedWeb della scienzaGoogle Scholar
↵Binder , JR , Desai , RH , Graves , WW e Conant , LL ( 2009 ). Dov'è il sistema semantico? Una revisione critica e una meta-analisi di 120 studi di neuroimaging funzionale .Cortecciacerebrale , 19 ( 12 ) , 2767-2796 .CrossRefPubMedWeb della scienzaGoogle Scholar
↵Efron , B. e Tibshirani , RJ ( 1994 ). Un'introduzione al bootstrap . CRC press .Google Scholar
↵Fedorenko , E. e Thompson-Schill , SL ( 2014 ). Rielaborazione della rete linguistica . Tendenze nelle scienze cognitive , 18 ( 3 ), 120 – 126 .CrossRefPubMedWeb della scienzaGoogle Scholar
↵Fedorenko , E. , Hsieh , P.-J. , Nieto-Castanon , A. , Whitfield-Gabrieli , S. , e Kanwisher , N. ( 2010 ). Nuovo metodo per le indagini fMRI sul linguaggio: definizione funzionale delle ROI nei singoli soggetti . Giornale di Neurofisiologia , 104 ( 2 ), 1177 – 1194 .CrossRefPubMedWeb della scienzaGoogle Scholar
↵Fedorenko , E. , Scott , TL , Brunner , P. , Coon , WG , Pritchett , B. , Schalk , G. e Kanwisher , N. ( 2016 ). Correlato neurale della costruzione del significato della frase . Atti della National Academy of Sciences , 113 ( 41 ), E6256 – E6262 .Abstract / Testo completo GRATUITOGoogle Scholar
↵Fischl , B. ( 2012 ). Freesurfer . Neuroimmagine , 62 ( 2 ), 774 – 781 .CrossRefPubMedWeb della scienzaGoogle Scholar
↵Frankland , SM e Greene , JD ( 2015 ). Un'architettura per la codifica del significato delle frasi nella corteccia temporale medio-superiore sinistra . Attidella National Academy of Sciences , 112 ( 37 ), 11732-11737 .Abstract / Testo completo GRATUITOGoogle Scholar
↵Friederici , AD ( 2011 ). Le basi cerebrali dell'elaborazione del linguaggio: dalla struttura alla funzione . Revisioni fisiologiche , 91 ( 4 ), 1357 – 1392 .CrossRefPubMedGoogle Scholar
↵Fyshe , A. , Sudre , G. , Wehbe , L. , Rafidi , N. e Mitchell , TM ( 2019 ). La semantica lessicale dei sintagmi aggettivo-sostantivo nel cervello umano . Mappatura del cervello umano , 40 ( 15 ), 4457 – 4469 .CrossRefGoogle Scholar
↵Gao , JS , Huth , AG , Lescroart , MD e Gallant , JL ( 2015 ). Pycortex: un visualizzatore di superfici interattivo per fmri . Frontiere nella neuroinformatica , 9 , 23 .Google Scholar
↵Gardner , M. , Grus , J. , Neumann , M. , Tafjord , O. , Dasigi , P. , Liu , NF , Peters , M. , Schmitz , M. e Zettlemoyer , L. ( 2018 ).didel linguaggio naturale semantica profonda . In Atti del workshop per NLP Open Source Software (NLP-OSS) , pagine 1-6 .Google Scholar
↵Hagoort , P. ( 2020 ). Il meccanismo (i) di creazione del significato dietro gli occhi e tra le orecchie . Philosophical Transactions of the Royal Society B , 375 ( 1791 ), 20190301 .Google Scholar
↵Halgren , E. , Dhond , RP , Christensen , N. , Van Petten , C. , Marinkovic , K. , Lewine , JD e Dale , AM ( 2002 ). Risposte magnetoencefalografiche simili a N400 modulate dal contesto semantico, dalla frequenza delle parole e dalla classe lessicale nelle frasi . Neuroimage , 17 ( 3 ), 1101 – 1116 .CrossRefPubMedWeb della scienzaGoogle Scholar
↵Hall , EL , Robson , SE , Morris , PG e Brookes , MJ ( 2014 ).relazione tra meg e fmri. Neuroimage , 102 , 80-91 .Google Scholar
↵Hickok , G. e Poeppel , D. ( 2007 ). L'organizzazione corticale dell'elaborazione del linguaggio . Nature Reviews Neuroscience , 8 ( 5 ), 393 – 402 .CrossRefPubMedWeb della scienzaGoogle Scholar
↵Holm , S. ( 1979 ). Una semplice procedura di test multipli sequenzialmente rigettanti .Rivistascandinava di statistica , pagine 65-70 .Google Scholar
↵Hultén , A. , Schoffelen , J.-M. , Uddén , J. , Lam , NH e Hagoort , P. ( 2019 ). Come il cervello dà senso oltre l'elaborazione di singole parole: uno studiomega. Neuroimage , 186 , 586–594 .Google Scholar
↵Huth , AG , de Heer , WA , Griffiths , TL , Theunissen , FE , Gallant , JL , Heer , W. a. D. , Griffiths , TL e Gallant , JL ( 2016 ).tappezzanola corteccia cerebrale umana . Nature , 532 ( 7600 ), 453–458 .CrossRefPubMedGoogle Scholar
↵Jain , S. e Huth , A. ( 2018 ). Incorporare il contesto nei modelli di codifica del linguaggio per fmri . In Advances in neural information processing systems , pagine 6628-6637 .Google Scholar
↵Kay , KN , Naselaris , T. , Prenger , RJ e Gallant , JL ( 2008 ). Identificazione di immagini naturali dall'attività cerebrale umana . Nature , 452 ( 7185 ), 352 .CrossRefPubMedWeb della scienzaGoogle Scholar
↵Khandelwal , U. , He , H. , Qi , P. e Jurafsky , D. ( 2018 ). Nitido vicino, sfocato lontano: come i modelli linguistici neurali usano il contesto .In Atti del 56° incontro annuale dell'Associazione per la linguistica computazionale (Volume 1 : Articoli lunghi), pagine 284-294 .Google Scholar
↵King , J.-R. e Dehaene , S. ( 2014 ).rappresentazioni mentali: il metodo di generalizzazione temporale .Tendenze nelle scienze cognitive , 18 ( 4 ), 203-210 .CrossRefPubMedWeb della scienzaGoogle Scholar
↵Kuperberg , G. ( 2007 ). Meccanismi neurali della comprensione del linguaggio: sfide alla sintassi.Brain Research , 1146 , 23-49 .Google Scholar
↵Kuperberg , GR , Holcomb , PJ , Sitnikova , T. , Greve , D. , Dale , AM e Caplan , D. ( 2003 ). Modelli distinti di modulazione neurale durante l'elaborazione di anomalie concettuali e sintattiche . Journal of Cognitive Neuroscience , 15 ( 2 ), 272 – 293 .CrossRefPubMedWeb della scienzaGoogle Scholar
↵Kutas , M. e Federmeier , KD ( 2011 ). Trent'anni e oltre: trovare un significato nella componente n400 del potenziale cerebrale evento-correlato (ERP) . Revisioneannuale di psicologia , 62 , 621-647 .Google Scholar
↵Lyu , B. , Choi , HS , Marslen-Wilson , WD , Clarke , A. , Randall , B. e Tyler , LK ( 2019 ). Dinamica neurale della composizione semantica . Atti della National Academy of Sciences , 116 ( 42 ), 21318 – 21327 .Abstract / Testo completo GRATUITOGoogle Scholar
↵Makin , JG , Moses , DA e Chang , EF ( 2020 ). Traduzione automatica dell'attività corticale in testo con un framework codificatore-decodificatore . Rapporto tecnico , Nature Publishing Group .Google Scholar
↵Miller , J. ( 1988 ). Un avvertimento sul tempo di reazione mediano . Journal of Experimental Psychology: Human Perception and Performance , 14 ( 3 ), 539 .CrossRefPubMedGoogle Scholar
↵Mitchell , T. , Shinkareva , S. , Carlson , A. , Chang , K. , Malave , V. , Mason , R. e Just , M. ( 2008 ).l' attività cerebrale umana associata al significato dei nomi .Science , 320 ( 5880 ) , 1191-1195 .Abstract / Testo completo GRATUITOGoogle Scholar
↵Nishimoto , S. , Vu , A. , Naselaris , T. , Benjamini , Y. , Yu , B. e Gallant , J. ( 2011 ). Ricostruzione delle esperienze visive dall'attività cerebrale evocata da film naturali . Current Biology .Google Scholar
↵Pallier , C. , Devauchelle , A. e Dehaene , S. ( 2011 ). Rappresentazione corticale della struttura costituente delle frasi . Attidella National Academy of Sciences , 108 ( 6 ), 2522-2527 .Abstract / Testo completo GRATUITOGoogle Scholar
↵Peters , ME , Neumann , M. , Iyyer , M. , Gardner , M. , Clark , C. , Lee , K. e Zettlemoyer , L. ( 2018 ). Rappresentazioni di parole contestualizzate profonde . In Atti di NAACL-HLT ,pagine 2227-2237 .Google Scholar
↵Pylkkänen , L. ( 2020 ). Basi neurali della composizione di base: cosa abbiamo imparato dagli studi sulla barca rossa e dalle loro estensioni . Philosophical Transactions of the Royal Society B , 375 ( 1791 ), 20190299 .Google Scholar
↵Rowling , J. ( 2012 ). Harry Potter e la pietra filosofale . Harry Potter US. Pottermore Limited .Google Scholar
↵Sheppard , K. , Khrapov , S. , Lipták , G. , mikedeltalima , Capellini , R. , Hugle , esvhd , Fortin , A. , Jpn , Adams , A. , jbrockmendel , Rabba , M. , Rose , ME , Rochette , T. , RENE-CORAIL , X. , e sincronizzazione ( 2020 ). bashtage/arch: versione 4.15 .Google Scholar
↵Skeide , MA e Friederici , AD ( 2016 ). L'ontogenesi della rete linguistica corticale . Nature Reviews Neuroscience , 17 ( 5 ), 323 – 332 .Google Scholar
↵Sudre , G. , Pomerleau , D. , Palatucci , M. , Wehbe , L. , Fyshe , A. , Salmelin , R. e Mitchell , T. ( 2012 ). Tracciamento della codifica neurale delle caratteristiche percettive e semantiche dei nomi concreti . Neuroimage , 62 , 451-463 .Google Scholar
↵Taulu , S. e Simola , J. ( 2006 ). Metodo di separazione dello spazio del segnale spaziotemporale per rifiutare l'interferenza vicina nelle misurazioni MEG . Fisica in medicina e biologia , 51 ( 7 ), 1759 .CrossRefPubMedGoogle Scholar
↵Taulu , S. , Kajola , M. e Simola , J. ( 2004 ). Soppressione di interferenze e artefatti mediante il metodo di separazione dello spazio del segnale . Topografia cerebrale , 16 ( 4 ) , 269-275 .CrossRefPubMedWeb della scienzaGoogle Scholar
↵Tenney , I. , Xia , P. , Chen , B. , Wang , A. , Poliak , A. , McCoy , RT , Kim , N. , Van Durme , B. , Bowman , S. , Das , D. , et al. ( 2019 ). Cosa impari dal contesto? Esplorando la struttura della frase nelle rappresentazioni di parole contestualizzate . Nella 7a Conferenza Internazionale sulle Rappresentazioni dell'Apprendimento, ICLR 2019 .Google Scholar
↵Toneva , M. e Wehbe , L. ( 2019 ).del linguaggio naturale (nelle macchine) con l'elaborazione del linguaggio naturale (nel cervello) . In Advances in Neural Information Processing Systems , pagine 14928-14938 .Google Scholar
Visser , M. , Jefferies , E. e Lambon Ralph , M. ( 2010 ). Elaborazione semantica nei lobi temporali anteriori: una meta-analisi della letteratura sulla neuroimmagine funzionale .Journalof cognitive neuroscience , 22 ( 6 ), 1083-1094 .CrossRefPubMedWeb della scienzaGoogle Scholar
Wehbe , L. , Vaswani , A. , Knight , K. e Mitchell , T. ( 2014a ). Allineamento di modelli statistici del linguaggio basati sul contesto con l'attività cerebrale durante la lettura . Negli Atti della Conferenza del 2014 sui metodi empirici nell'elaborazione del linguaggio naturale (EMNLP) .Google Scholar
↵Wehbe , L. , Murphy , B. , Talukdar , P. , Fyshe , A. , Ramdas , A. e Mitchell , T. ( 2014b ). Scoperta simultanea dei modelli delle regioni cerebrali coinvolte nei diversi sottoprocessi di lettura delle storie . PloS one , 9 ( 11 ), e112575 .CrossRefPubMedGoogle Scholar
↵Wehbe , L. , Ramdas , A. , Steorts , RC e Shalizi , CR ( 2015 ).Letturadel cervello regolarizzata con restringimento e levigatura . Annals of Applied Statistics , 9 ( 4 ), 1997-2022 .Google Scholar
Commenti
Posta un commento